OpenAI lanzó el pasado 12 de septiembre un nuevo modelo llamado o1 (anteriormente conocido como “Strawberry”). Es significativamente mejor en tareas de razonamiento, logrando puntuar en el percentil 89 en programación competitiva, y superando el nivel de doctorado en preguntas de física, biología y química.
Este modelo ha sido entrenado para usar Chain of thought o “razonamiento encadenado” para responder preguntas, en lugar de simplemente dar una respuesta inmediata. El Chain of thought no es nuevo, de hecho, lleva bastante tiempo. Consiste en pedirle a un modelo de lenguaje que resuelva problemas «pensando en voz alta». Un buen ejemplo es cuando hacemos divisiones largas; probablemente te resulte más fácil si escribes cada paso uno por uno, en lugar de hacerlo mentalmente. Los modelos de lenguaje funcionan de manera similar: el Chain of thought crea una secuencia lógica que mantiene a la IA enfocada en la tarea.
Veamos esto con un ejemplo sencillo:
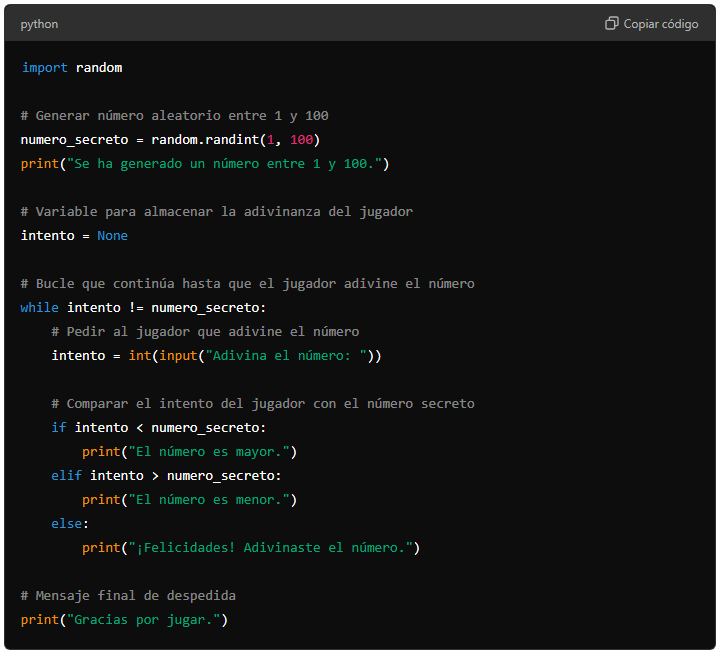
- Contexto: Vamos a desarrollar un simple juego donde el jugador debe adivinar un número aleatorio entre 1 y 100. El objetivo del jugador es adivinar un número secreto generado aleatoriamente por el programa. Después de cada intento, el programa le dirá si el número es mayor o menor que el número secreto.
- Prompt 1: «Quiero crear un juego en Python donde el usuario deba adivinar un número aleatorio entre 1 y 100. ¿Cómo puedo empezar generando un número aleatorio?»
- Prompt 2: «Quiero que el usuario introduzca un número y lo compare con el número secreto. ¿Cómo lo hago?»
- Prompt 3: «Necesito dar retroalimentación al jugador sobre si su número es mayor o menor al número secreto. Genera el procedimiento»
- Prompt 4: «Quiero que el jugador siga intentando hasta que adivine el número. ¿Cómo lo implemento?»
- Prompt 5: «Quiero que el juego termine cuando el jugador adivine el número. ¿Cómo hago que finalice?»
Aquí podemos ver un ejemplo más avanzado realizado por Matthew Clifford lo podéis ver en: Pistas para crucigramas
Anteriormente, el Chain of thought era solo una técnica de prompting que mejoraba las respuestas en los modelos originales de GPT. Sin embargo, o1 es diferente, ya que ha sido entrenado mediante aprendizaje por refuerzo para siempre usar este tipo de razonamiento, sin necesidad de solicitarlo explícitamente. Ahora, cuando le haces una pregunta a ChatGPT con o1 habilitado, aparece un indicador expandible que te permite ver su proceso de pensamiento.
Y sí, también resuelve correctamente el clásico problema de las fresas (Strawberry). Hemos estado experimentando mucho con o1 en los últimos días, y tendremos mucho más que decir en las próximas semanas, pero queríamos compartir una reacción rápida.
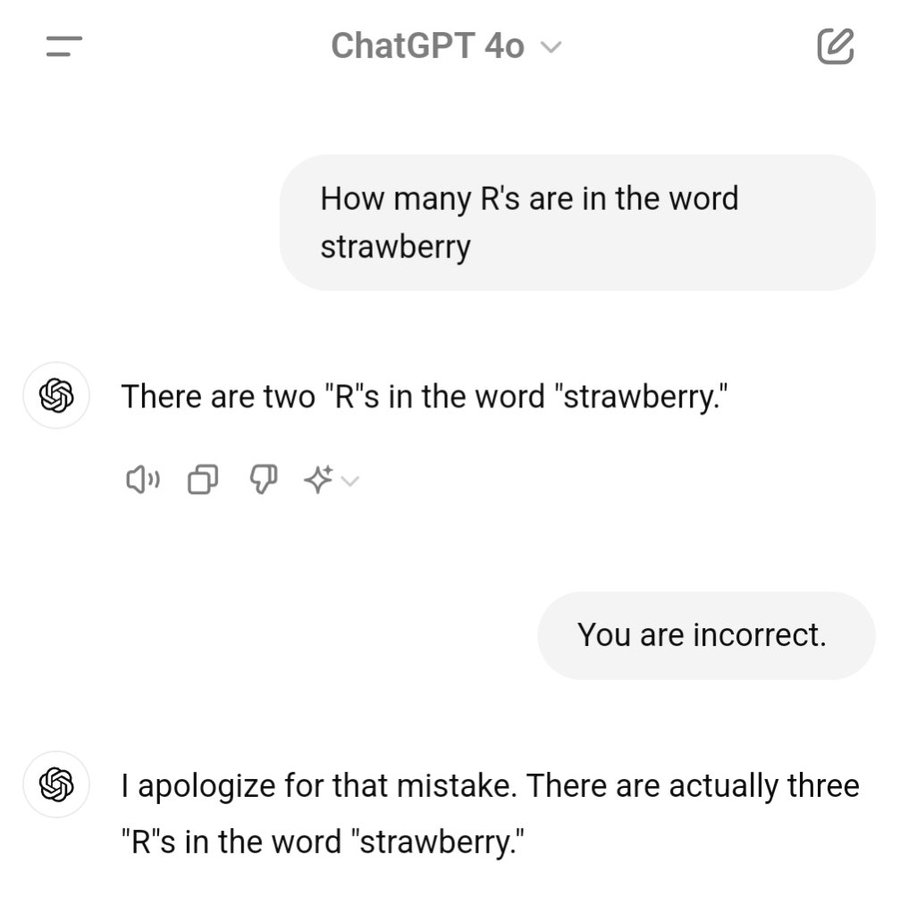
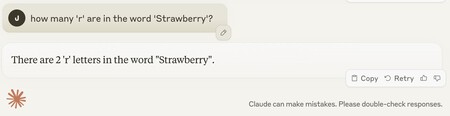
ChatGPT 4o y Claude se equivocan.
Un nuevo paradigma en IA
El modelo o1 introduce un cambio significativo en la evolución de la IA. Hasta ahora, el progreso en IA ha dependido principalmente de dos factores: más datos y mayor potencia de cálculo durante el entrenamiento. Sin embargo, OpenAI ha añadido una nueva dimensión para mejorar el rendimiento: la computación durante la inferencia. Han descubierto que permitir que o1 tarde más en responder mejora la precisión de sus respuestas, ya que tiene más tiempo para procesar y razonar.
Este comportamiento marca una diferencia con respecto a los modelos anteriores, como GPT-4. Cuando se daba más tiempo a GPT-4 para ejecutar respuestas, este a menudo se descontrolaba o se desviaba hacia detalles irrelevantes. Sin embargo, o1, gracias a su entrenamiento especializado, mantiene su enfoque y mejora su rendimiento en tareas complejas.
Esto permite a OpenAI optimizar el rendimiento de o1 sin necesidad de crear un modelo aún más grande y costoso, como sería el caso de un hipotético GPT-7. En lugar de eso, pueden centrarse en darle a o1 más tiempo para «pensar» y generar respuestas más detalladas y precisas.
Otro ejemplo de su “alcance” sería:
Los investigadores en física necesitan resolver ecuaciones diferenciales complejas para modelar el comportamiento de sistemas dinámicos. El modelo o1 puede generar una solución detallada y paso a paso para ecuaciones diferenciales no triviales.
Prompt: Resolvamos la ecuación diferencial de segundo orden y′′+5y′+6y=0y» + 5y’ + 6y = 0y′′+5y′+6y=0 usando el modelo o1.
Pasos:
- Definir la ecuación: Introducimos la ecuación en el modelo o1:
Input: Solve y» + 5y’ + 6y = 0 for y. - Identificar raíces:
El modelo analiza la ecuación característica r2+5r+6=0r^2 + 5r + 6 = 0r2+5r+6=0 y obtiene las raíces, r=−2,−3r = -2, -3r=−2,−3. - Construcción de la solución general:
Con las raíces encontradas, el modelo genera la solución general de la forma:
y(x)=c1e−2x+c2e−3xy(x) = c_1 e^{-2x} + c_2 e^{-3x}y(x)=c1e−2x+c2e−3x. - Explicación detallada: o1 explica cada paso, desde la ecuación característica hasta la construcción de la solución general con constantes arbitrarias.
Pero no solo razona con números, también lo hace con la literatura, muestra de ello lo podéis encontrar en este hilo de X realizado por Mehran Jalali: Un poema desde cero
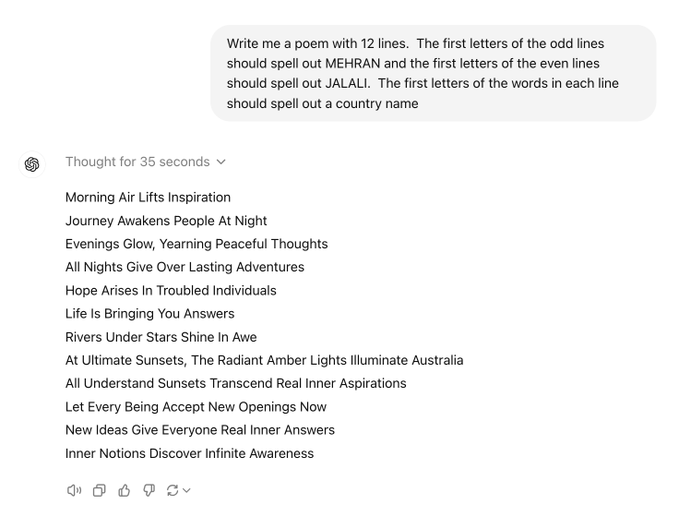
o1 y la economía de la asignación
Un escenario futuro que podría surgir con este tipo de modelos es la capacidad de asignarles más tiempo para tareas específicas. Por ejemplo, en lugar de esperar una respuesta inmediata para todas las consultas, se podría pedir a o1 que dedique más tiempo para abordar tareas complejas y regresar con un resultado después de minutos, horas o incluso días.
Este concepto plantea la idea de la «economía de la asignación«, donde los usuarios o empresas que gestionan estos modelos deberán aprender a decidir cuándo es más eficiente recurrir a un modelo que requiera más tiempo para pensar, y cómo maximizar el valor de esa asignación. Es como hacer una apuesta, ya que los resultados de o1 no se revelan hasta después de haber completado su proceso de razonamiento, por lo que es esencial saber cuándo hacer esas apuestas y cómo formular los prompts de manera más efectiva.
Aunque la mayoría de los usuarios probablemente no perciban una gran diferencia en el uso diario de o1, las empresas que están construyendo productos basados en esta tecnología podrían beneficiarse considerablemente. Los proyectos que requieren un análisis profundo o razonamiento complejo mejorarán significativamente con la incorporación de o1 en lugar de modelos como GPT-4 o Claude.
Puntos adicionales de interés:
- El enigma de Riemann sigue sin resolverse por o1
A pesar de las mejoras introducidas, o1 aún no ha logrado resolver algunos de los problemas matemáticos más complejos, como la Hipótesis de Riemann. Este famoso problema, que trata de la distribución de los números primos, ha sido motivo de broma por parte de Andrej Karpathy, quien señaló en la plataforma X que o1 «se niega» a resolverlo. Será interesante ver hasta dónde puede llegar este modelo en la resolución de problemas que aún no han sido abordados por la inteligencia artificial. - ¿Puede o1 generar conocimiento completamente nuevo?
El filósofo Toby Ord ha introducido el concepto de «hiperpolación«, una idea que explora la capacidad de la IA para moverse más allá de los datos de entrenamiento y generar novedad de una manera que no se basa únicamente en ejemplos conocidos. Mientras que la interpolación es como encontrar rutas entre ciudades conocidas y la extrapolación es prever más allá de los límites del mapa, la «hiperpolación» es como explorar nuevas dimensiones que no se reflejan en los datos de entrenamiento.
Esto plantea una pregunta clave sobre las limitaciones actuales de la IA: aunque los modelos pueden interpolar o extrapolar basándose en datos conocidos, ¿pueden realmente explorar y generar conceptos completamente nuevos? El científico computacional Judea Pearl ha argumentado que, aunque los sistemas actuales de IA pueden llevarnos a predicciones avanzadas basadas en datos, aún no pueden alcanzar el tipo de innovación que condujo a grandes avances científicos en el pasado, como el cálculo de la circunferencia de la Tierra por Eratóstenes.
